math
-
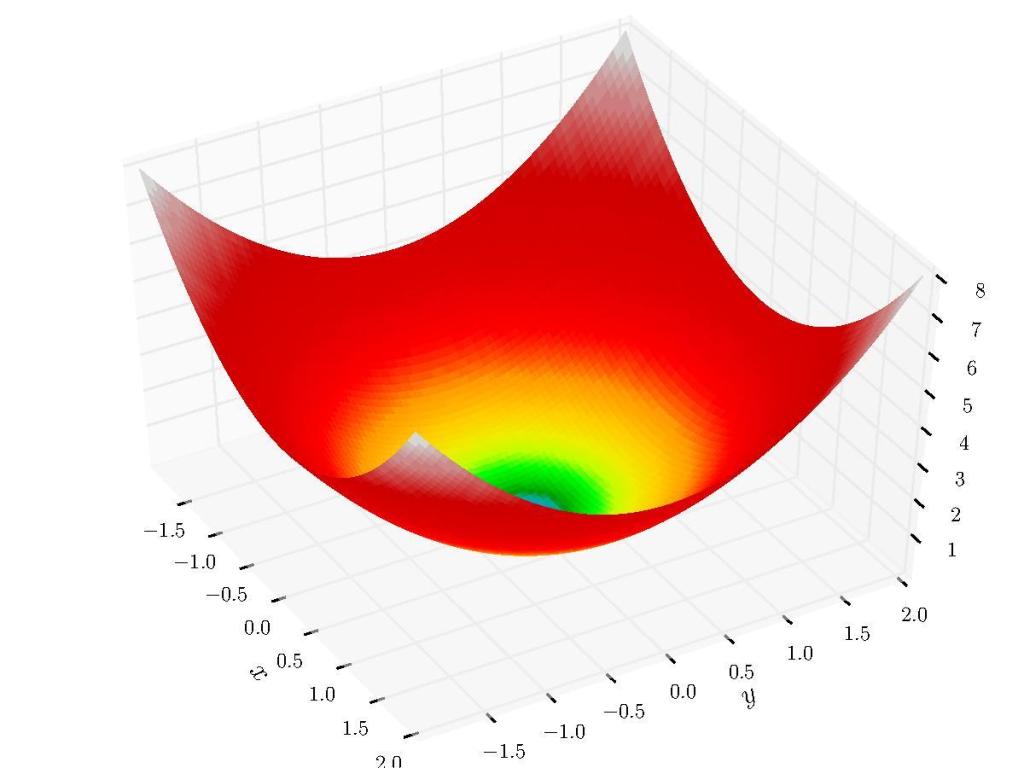
Broyden’s Method in Python
In a previous post we looked at root-finding methods for single variable equations. In this post we’ll look at the expansion of Quasi-Newton methods to the multivariable case and look at one of the more widely-used algorithms today: Broyden’s Method.
-
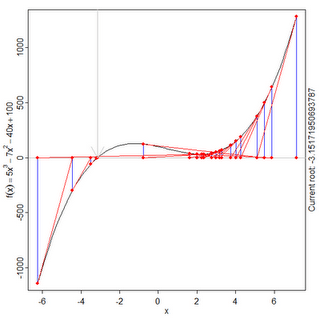
Root-Finding Algorithms Tutorial in Python: Line Search, Bisection, Secant, Newton-Raphson, Inverse Quadratic Interpolation, Brent’s Method
Motivation How do you find the roots of a continuous polynomial function? Well, if we want to find the roots of something like:
-
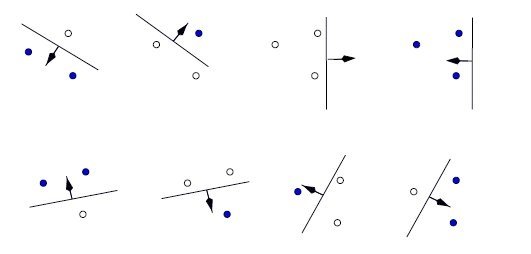
Statistical Learning Theory: VC Dimension, Structural Risk Minimization
Sometimes our models overfit, sometimes they overfit. A model’s capacity is, informally, its ability to fit a wide variety of functions. As a simple example, a linear regression model with a single parameter has a much lower capacity than a linear regression model with multiple polynomial parameters. Different datasets demand models of different capacity, and…
-
The Box-Cox Transformation
The Box-Cox transformation is a family of power transform functions that are used to stabilize variance and make a dataset look more like a normal distribution. Lots of useful tools require normal-like data in order to be effective, so by using the Box-Cox transformation on your wonky-looking dataset you can then utilize some of these tools. Here’s the…
-
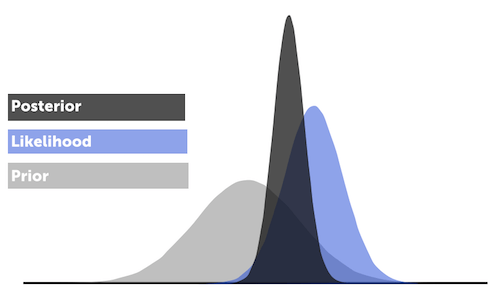
MLE, MAP, and Naive Bayes
Suppose we are given a dataset of outcomes from some distribution parameterized by . How do we estimate ? For example, given a bent coin and a series of heads and tails outcomes from that coin, how can we estimate the probability of the coin landing heads?