In a previous post we looked at root-finding methods for single variable equations. In this post we’ll look at the expansion of Quasi-Newton methods to the multivariable case and look at one of the more widely-used algorithms today: Broyden’s Method.

Broyden’s Good Method
Broyeden’s Method is, like the Secant Method and Brent’s Method, another attempt to use information about the derivatives without having to explicitly and expensively calculate them at each iteration. For Broyden’s Method, we begin with an initial estimate of the Jacobian and update it at each iteration based on the new position of our guess vector 
Recall that for the Taylor expansion of our function f is:

where 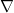
When we set 

And solving for 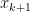
![x_{k+1} = x_k - [\nabla f(x_k)]^{-1} f(x_k)](https://s0.wp.com/latex.php?latex=x_%7Bk%2B1%7D+%3D+x_k+-+%5B%5Cnabla+f%28x_k%29%5D%5E%7B-1%7D+f%28x_k%29&bg=ffffff&fg=000&s=0&c=20201002)
At each iteration, instead of calculating and recalculating the Jacobian, we approximate it with a matrix 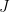

i.e. to minimize

while also imposing the secant condition:

The minimization of the norm just helps make sure the Jacobian doesn’t change too rapidly, while imposing the secant condition makes sense; revisiting the secant condition, it basically says “the rate of change (Jacobian) of the function multiplied by a change in input had better equal the change in output of the function applied to that same change in input,” or 
Using a Lagrange multiplier 

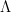

Differentiating w.r.t 


Substituting into 


This gives us our update rule for the Jacobian:



First we have Broyden’s Method (good), which follows the update rule above. For better legibility, variables are more concise than the update formula given above.
from __future__ import division
import numpy as np
import scipy.linalg as sla
def broyden_good(x, y, f_equations, J_equations, tol=10e-10, maxIters=50):
steps_taken = 0
f = f_equations(x,y)
J = J_equations(x,y)
while np.linalg.norm(f,2) > tol and steps_taken < maxIters:
s = sla.solve(J,-1*f)
x = x + s[0]
y = y + s[1]
newf = f_equations(x,y)
z = newf - f
J = J + (np.outer ((z - np.dot(J,s)),s)) / (np.dot(s,s))
f = newf
steps_taken += 1
return steps_taken, x, y
tol = 10.0** -15
maxIters = 50
x0 = 1
y0 = 2
def fs(x,y):
return np.array([x + 2*y - 2, x**2 + 4*y**2 - 4])
def Js(x,y):
return np.array([[1,2],
[2, 16]])
n, x, y = broyden_good(x0, y0, fs, Js, tol, maxIters=50 )
print "iterations: ", n
print "x and y: ", x, y
iterations: 8 x and y: 8.15906707552e-17 1.0
For reference, the correct solution to this system of equations:


is [0,1].
Broyden’s Bad Method
I’m not clear on the reason for calling one good and the other bad; so far as I know Broyden and other early users obtained better numerical accuracy using the above version. However, the “bad” version that follows carries with it an important concept that is used for lots of optimization algorithms.
In computing our updates to x via:
We had to invert the matrix J at each iteration. (Remember that matrix inversion is an O(n^3) operation.) The motivation behind Broyden’s bad algorithm is: instead of doing that expensive computation at each step, what if we just store and update the inverse Jacobian at each iteration?
The result is a much faster algorithm with a different update rule obtained from the Sherman-Morrison formula:

where 
![u = J_k [f(x_k) - f(x_{k-1})]](https://s0.wp.com/latex.php?latex=u+%3D+J_k+%5Bf%28x_k%29+-+f%28x_%7Bk-1%7D%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
from __future__ import division
import numpy as np
import scipy.linalg as sla
from numpy.linalg import inv
def broyden_bad(x, y, f_equations, J_equations, tol=10e-10, maxIters=50):
steps_taken = 0
f = f_equations(x,y)
J = inv(J_equations(x,y))
while np.linalg.norm(f,2) > tol and steps_taken <span data-mce-type="bookmark" id="mce_SELREST_start" data-mce-style="overflow:hidden;line-height:0" style="overflow:hidden;line-height:0" ></span><span data-mce-type="bookmark" id="mce_SELREST_start" data-mce-style="overflow:hidden;line-height:0" style="overflow:hidden;line-height:0" ></span>< maxIters:
s = J.dot(f_equations(x,y))
x = x - s[0]
y = y - s[1]
newf = f_equations(x,y)
z = newf - f
u = J.dot(z)
d = - 1 * s
J = J + np.dot(((d-u).dot(d)), J) / np.dot(d,u)
f = newf
steps_taken += 1
return steps_taken, x, y
tol = 10.0** -15
maxIters = 50
x0 = 1
y0 = 2
def fs(x,y):
return np.array([x + 2*y - 2, x**2 + 4*y**2 - 4])
def Js(x,y):
return np.array([[1,2],
[2, 16]])
B = np.array([[1,2],
[2, 16]])
n, x, y = broyden_bad(x0, y0, fs, Js, tol, maxIters=50 )
print "iterations: ", n
print "x and y: ", x, y
iterations: 8 x and y: 1.81816875617e-16 1.0
References
