Motivation
How do you find the roots of a continuous polynomial function? Well, if we want to find the roots of something like:

you might remember the quadratic formula from middle school, and for similarly low-degree polynomial functions, various analytical methods are at your disposal.
However, for higher-degree polynomials (five or higher) where there are no general analytic solutions or for complicated functions (or sets of functions), it is often necessary or easier to resort to numeric methods – this is where root-finding algorithms come in.
Root-finding algorithms share a very straightforward and intuitive approach to approximating roots. The general structure goes something like: a) start with an initial guess, b) calculate the result of the guess, c) update the guess based on the result and some further conditions, d) repeat until you’re satisfied with the result.

For example, how would you go about calculating the square root of 20 by hand? You’d begin with something like 4.5 (you have the luxury of knowing what a good first guess is – this is not always the case), square it to get 20.25, reduce 4.5 by some small amount since the result is greater than 20, recalculate, etc. until you get an answer you’re satisfied with. Our naive root-finding algorithm looks something like this:
Naive Method / Line Search
def naive_root(f, x_guess, tolerance, step_size):
steps_taken = 0
while abs(f(x_guess)) > tolerance:
if f(x_guess) > 0:
x_guess -= step_size
elif f(x_guess) < 0:
x_guess += step_size
else:
return x_guess
steps_taken += 1
return x_guess, steps_taken
f = lambda x: x**2 - 20
root, steps = naive_root(f, x_guess=4.5, tolerance=.01, step_size=.001)
print "root is:", root
print "steps taken:", steps
root is: 4.473 steps taken: 27
Not bad – we approximated one root of our function to the desired specificity. We’ve essentially re-invented a line-search method:

where each guess is a function of the previous guess, plus some step size 
But there are a few unsatisfactory things about the algorithm. First, if you run the algorithm with a tolerance of .001 (precision down to one more decimal place) you’ll find that execution never completes. This is because our step size is too large: at some point f(x-guess) bounces back and forth over the “true” root between a guess that’s too small and a guess that’s too large, both of which are greater than the absolute value of our tolerance. So we need to be careful about the balance between the step size and our tolerance, and we’d likely need to set a limit on the maximum number of iterations in our loop to halt the program should this occur again.
The second related problem has to do with our step size. If we had started with an initial guess of 5 instead of 4.5, we would have to do 527 iterations instead of 27 iterations in order to find a root. Surely the step size could be improved by taking into account just how far we are from the root; for example, we might factor in something like 
While factoring the squared error into our step size doesn’t work very well in practice, this fundamental idea of finding new ways to optimize step size (and direction) is the foundation for the root-finding algorithms that follow. Having developed an intuition for the naive method of root finding, remaining algorithms are variations on a theme.
Bisection Method
The bisection method introduces a simple idea to hone in on the root. Start with two guesses such that f(guess_1) and f(guess_2) are of opposite sign. This means that we have one guess that’s too large and another guess that’s too small. The idea is to gradually squeeze the guess that’s too high and the guess that’s too low towards zero until we’re satisfied that the range between the two is small enough or equal to zero.
At each step we take the midpoint of the two guesses. If the midpoint is zero (the guesses are the same) or if the guesses are sufficiently close to one another, we return the midpoint. Otherwise, if the f(midpoint) is negative, then we replace the lower bound with the midpoint, and if f(midpoint) is positive, then we replace the upper bound with the midpoint. And, of course, repeat.
from __future__ import division<span data-mce-type="bookmark" id="mce_SELREST_start" data-mce-style="overflow:hidden;line-height:0" style="overflow:hidden;line-height:0" ></span>
def bisection(f, lower, upper, max_iters=50, tolerance=1e-5):
steps_taken = 0
while steps_taken < max_iters:
m = (lower + upper) / 2.0
if m == 0 or abs(upper-lower) < tolerance: return m, steps_taken if f(m) > 0:
upper = m
else:
lower = m
steps_taken += 1
final_estimate = (lower + upper) / 2.0
return final_estimate, steps_taken
f = lambda x: x**2 - 20
root, steps = bisection(f, 1, 8)
print "root is:", root
print "steps taken:", steps
root is: 4.47213888168 steps taken: 20
Newton-Raphson Method
You’ve probably guessed that the derivative is an obvious candidate for improving step sizes: the derivative tells us about the direction and step size to take on reasonably convex, continuous, well-behaved functions; all we need to do is find a point on the curve where the derivative is zero.
For Newton-Raphson, we supply an initial guess, calculate the derivative of f at the initial guess, calculate where the derivative intersects the x-axis, and use that as our next guess. For this code we approximate the derivative of univariate f at x so that you can play around with the function without having to calculate the derivatives, but you can easily substitute in the actual derivative function to get similar results. The method can be extended to n dimensions with the Jacobian and/or higher orders of the Taylor series expansion, but for now we’ll keep it simple.
from __future__ import division
def discrete_method_approx(f, x, h=.00000001):
return (f(x+h) - f(x)) / h
def newton_raphson(f, x, tolerance=.001):
steps_taken = 0
while abs(f(x)) > tolerance:
df = discrete_method_approx(f, x)
x = x - f(x)/df
steps_taken += 1
return x, steps_taken
f = lambda x: x**2 - 20
root, steps = newton_raphson(f, 8)
print "root is:", root
print "steps taken:", steps
root is: 4.47213597002 steps taken: 4
Note that the update rule:
![x_{n+1} = x_{n} - [df(x_{n})]^{-1} f(x_{n})](https://s0.wp.com/latex.php?latex=x_%7Bn%2B1%7D+%3D+x_%7Bn%7D+-+%5Bdf%28x_%7Bn%7D%29%5D%5E%7B-1%7D+f%28x_%7Bn%7D%29&bg=ffffff&fg=000&s=0&c=20201002)
just solves the tangent line for y=0.
As we can see, this method takes far fewer iterations than the Bisection Method, and returns an estimate far more accurate than our imposed tolerance (Python gives the square root of 20 as 4.47213595499958).
The drawback with Newton’s Method is that we need to compute the derivative at each iteration. While it wasn’t a big deal for our toy problem, computing gradients and higher order derivatives for large, complex systems of equations can be very expensive. So while Newton’s Method may find a root in fewer iterations than Algorithm B, if each of those iterations takes ten times as long as iterations in Algorithm B then we have a problem. To remedy this, let’s look at some Quasi-Newtonian methods
Quasi-Newtonian: Secant Method
The idea of the Quasi-Newtonian Secant Method and other Quasi-Newtonian methods is to substitute the expensive calculation of the derivative/Jacobian/Hessian at each step with an inexpensive but good-enough approximation. All of the more popular methods (BFGS, Secant, Broyden, etc.) have the same basic form, save for different rules about how best to approximate the gradient and update the guess.
You can think of the Secant Method as derivative-lite. Instead of computing the derivative, we approximate it using two points (x0, f(x0)) and (x1, f(x1)), calculate where the line intercepts the x-axis, and use that as one of our new points. This provides a fast way to generate a line that should approximate the tangent line to the function somewhere between these two points
Given our two initial guesses 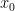


Setting y to 0 (our new guess is where the line intercepts the x-axis), we get:

def secant_method(f, x0, x1, max_iter=100, tolerance = 1e-5):
steps_taken = 1
while steps_taken < max_iter and abs(x1-x0) > tolerance:
x2 = x1 - ( (f(x1) * (x1 - x0)) / (f(x1) - f(x0)) )
x1, x0 = x2, x1
steps_taken += 1
return x2, steps_taken
f = lambda x: x**2 - 20
root, steps = secant_method(f, 2, 8)
print "root is:", root
print "steps taken:", steps
root is: 4.4721359553 steps taken: 7
Inverse Quadratic Interpolation and Lagrange Polynomials
This method is similar to the secant method but instead is initialized with three points, interpolates a polynomial curve based on those points, calculates where the curve intercepts the x-axis and uses this point as the new guess in the next iteration.
The quadratic interpolation method is the Lagrange polynomial:

where

is carried out with three points to get a second degree polynomial curve. Basically, in this instance we create three basic 

def inverse_quadratic_interpolation(f, x0, x1, x2, max_iter=20, tolerance=1e-5):
steps_taken = 0
while steps_taken < max_iter and abs(x1-x0) > tolerance: # last guess and new guess are v close
fx0 = f(x0)
fx1 = f(x1)
fx2 = f(x2)
L0 = (x0 * fx1 * fx2) / ((fx0 - fx1) * (fx0 - fx2))
L1 = (x1 * fx0 * fx2) / ((fx1 - fx0) * (fx1 - fx2))
L2 = (x2 * fx1 * fx0) / ((fx2 - fx0) * (fx2 - fx1))
new = L0 + L1 + L2
x0, x1, x2 = new, x0, x1
steps_taken += 1
return x0, steps_taken
f = lambda x: x**2 - 20
root, steps = inverse_quadratic_interpolation(f, 4.3, 4.4, 4.5)
print "root is:", root
print "steps taken:", steps
root is: 4.4721359579 steps taken: 2
Brent’s Method
Brent’s Method seeks to combine the robustness of the bisection method with the fast convergence of inverse quadratic interpolation. The basic idea is to switch between inverse quadratic interpolation and bisection based on the step performed in the previous iteration and based on inequalities gauging the difference between guesses:
def brents(f, x0, x1, max_iter=50, tolerance=1e-5):
fx0 = f(x0)
fx1 = f(x1)
assert (fx0 * fx1) <= 0, "Root not bracketed"
if abs(fx0) < abs(fx1):
x0, x1 = x1, x0
fx0, fx1 = fx1, fx0
x2, fx2 = x0, fx0
mflag = True
steps_taken = 0
while steps_taken < max_iter and abs(x1-x0) > tolerance:
fx0 = f(x0)
fx1 = f(x1)
fx2 = f(x2)
if fx0 != fx2 and fx1 != fx2:
L0 = (x0 * fx1 * fx2) / ((fx0 - fx1) * (fx0 - fx2))
L1 = (x1 * fx0 * fx2) / ((fx1 - fx0) * (fx1 - fx2))
L2 = (x2 * fx1 * fx0) / ((fx2 - fx0) * (fx2 - fx1))
new = L0 + L1 + L2
else:
new = x1 - ( (fx1 * (x1 - x0)) / (fx1 - fx0) )
if ((new < ((3 * x0 + x1) / 4) or new > x1) or
(mflag == True and (abs(new - x1)) >= (abs(x1 - x2) / 2)) or
(mflag == False and (abs(new - x1)) >= (abs(x2 - d) / 2)) or
(mflag == True and (abs(x1 - x2)) < tolerance) or
(mflag == False and (abs(x2 - d)) < tolerance)):
new = (x0 + x1) / 2
mflag = True
else:
mflag = False
fnew = f(new)
d, x2 = x2, x1
if (fx0 * fnew) < 0:
x1 = new
else:
x0 = new
if abs(fx0) < abs(fx1):
x0, x1 = x1, x0
steps_taken += 1
return x1, steps_taken
f = lambda x: x**2 - 20
root, steps = brents(f, 2, 5, tolerance=10e-5)
print "root is:", root
print "steps taken:", steps
root is: 4.472135955 steps taken: 16
Which should I use?
How should we evaluate these algorithms? In general, we need to care about an algorithm’s:
- convergence rate (how fast it gets to an answer)
- what guarantees we have that the algorithm will converge at all
- computational expense in each step of the iteration
Quotient convergence is defined in terms of the ratio of successive error terms, or how much the error decreases per iteration. If 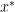



where C is finite and positive. Now, if:
- k=1 and C<1, the convergence rate is linear
- 1<k<2, the convergence rate is superlinear
- k=2, the convergence rate is quadratic
In other words, does the algorithm get better at a constant rate, a quadratic rate, or something inbetween?
I won’t go into great detail about the respective performance of each algorithm, but will give some general guidelines that should help you gain an intuition about which perform best under which conditions.
- Bisection is very robust and guaranteed to find an approximation in a fixed number of iterations, but is very slow: linear convergence. Each iteration is fast since we don’t compute any gradients, but convergence can be very slow. This method also works for non-continuous functions, so long as they can be evaluated at every point in the initial interval.
- Newton-Raphson converges very fast (quadratically), but requires good initial guesses. Since it uses the derivative, the function must be differentiable, the derivative must be supplied (or approximated, which can be a little expensive and slows convergence), and there is an assumption of convexity if we’re searching for a global minimum. The method can be expanded to n dimensions, and typically makes use of the Hessian (second term in Taylor expansion) to exploit information about curvature and to detect saddle points: the method works if the Hessian is positive definite and not ill-conditioned, but even in the case where it is semidefinite, mixed, or ill-conditioned, there are methods for regularizing the Hessian (see Section 8.6). In general though, the biggest drawback is calculating, inverting, and updating the Hessian, where inversion is O(n^3) for a n*n dimension matrix, repeated at every iteration.
- Secant Method has superlinear convergence, but is typically faster than Newton’s due to relatively inexpensive computation at each iteration. Like Newton’s, it requires good initial guesses.
- Inverse Quadratic Interpolation isn’t really used as a root-finding method on its own and is not recommended as such, but is important in discussing Brent’s.
- Brent’s is essentially the Bisection method augmented with IQI whenever such a step is safe. At it’s worst case it converges linearly and equal to Bisection, but in general it performs superlinearly; it combines the robustness of Bisection with the speedy convergence and inexpensive computation of Quasi-Newtonian methods. Because of this, you’re likely to find Brent’s as a default root-finding algorithm in popular libraries. For example, MATLAB’s fzero, used to find the root of a nonlinear function, employs a variation of Brent’s.
Some Excellent Resources:
- http://www.karenkopecky.net/Teaching/eco613614/Notes_RootFindingMethods.pdf
- Chapter 8 and Chapter 4 of Deep Learning
- http://heath.cs.illinois.edu/scicomp/notes/index.html
- http://people.duke.edu/~ccc14/sta-663-2016/11_OptimizationOneDimension.html
- https://www.brianheinold.net/notes/An_Intuitive_Guide_to_Numerical_Methods_Heinold.pdf
- And, of course, Wikipedia
