The Box-Cox transformation is a family of power transform functions that are used to stabilize variance and make a dataset look more like a normal distribution. Lots of useful tools require normal-like data in order to be effective, so by using the Box-Cox transformation on your wonky-looking dataset you can then utilize some of these tools.
Here’s the transformation in its basic form. For value 



Before getting to an example, I’ll ask and answer as best I can a few questions that seemed good to me, but (mostly) didn’t appear in any explanation of the subject that I could find.
- Why subtract 1 from
?
For all values of
- Why divide by lambda?
As a normalizing constant. As lambda increases, the effect of exponentiation increases, but so too does the division factor. Not on the same scale, but it still it has some normalizing effect. Also, this makes taking the first derivative a little nicer when it comes to evaluating the optimal value of
- Why is zero a different value?
When 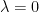
- Why log(x) at
As
- What about negative values in your dataset?
Straightforward solution is to include a shift parameter such that for all values x, x + shift parameter is positive. Box-Cox is a family of power transformations, and there are lots of variations that have different ways of dealing with exceptions like negative values, e.g. one proposed variation exponentiates the data values.
In practice, a Box-Cox function in a software package like scipy basically tries out a range of values for
So, let’s take some data and see what happens when we apply Box-Cox.

Great, we put in some data, removed outliers (we’ll revisit the removal of outliers a little later) and found the best value of
Here’s our data distribution before Box-Cox, where we see some unwanted skew and kurtosis (peakiness):

And here’s the probability plot for our data. A probability plot puts your data against data generated from a theoretical distribution, in this case the normal distribution. The data is scaled such that the straight line contains data points from a normal distribution; the closer our data is to this line, the more normal it is.

Again, you can see the right skew and high-variance data points on the right.
Here, we look at a range of

 Pretty cool, huh? As an aside, most explanations of Box-Cox mention that the search value for
Pretty cool, huh? As an aside, most explanations of Box-Cox mention that the search value for
Here’s our new probplot and distribution looking much more normal:


Out of curiosity, I ran the Box-Cox again, but this time left in 3 outliers sitting on the bottom range; it makes quite a difference. Note both the range of all values, as well as the range between where the left and right tails loosely begin and end: ~.03 for the above dataset, ~.6 for the dataset below.

