machine learning
-
BERT Fine-Tuning Tutorial with PyTorch
Here’s another post I co-authored with Chris McCormick on how to quickly and easily create a SOTA text classifier by fine-tuning BERT in PyTorch. This was created when BERT was pretty new and exciting, but the tooling for it was quite bad. Huggingface hosted the model, but documentation was very poor. As a result of…
-
BERT Word Embeddings Tutorial
Check out the post I co-authored with Chris McCormick on BERT Word Embeddings here. We take an in-depth look at the word embeddings produced by BERT, show you how to create your own in a Google Colab notebook, and tips on how to implement and use these embeddings in your production pipeline. This was created…
-
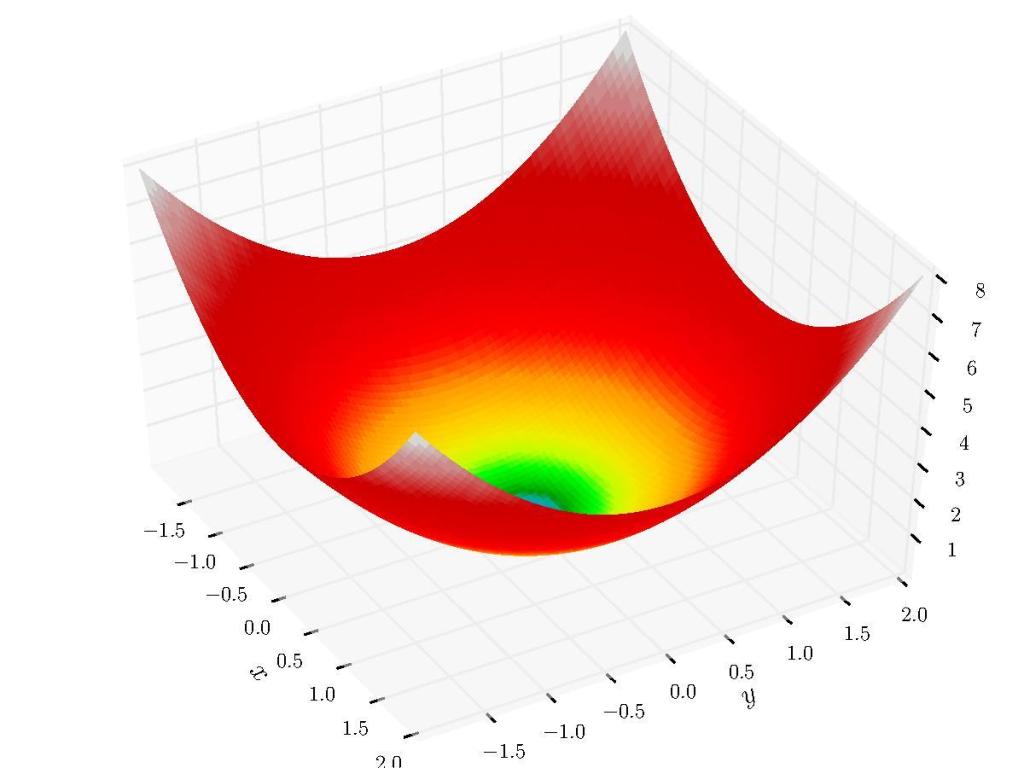
Broyden’s Method in Python
In a previous post we looked at root-finding methods for single variable equations. In this post we’ll look at the expansion of Quasi-Newton methods to the multivariable case and look at one of the more widely-used algorithms today: Broyden’s Method.
-
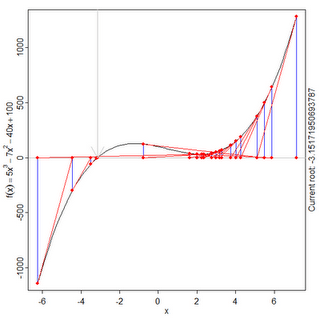
Root-Finding Algorithms Tutorial in Python: Line Search, Bisection, Secant, Newton-Raphson, Inverse Quadratic Interpolation, Brent’s Method
Motivation How do you find the roots of a continuous polynomial function? Well, if we want to find the roots of something like:
-
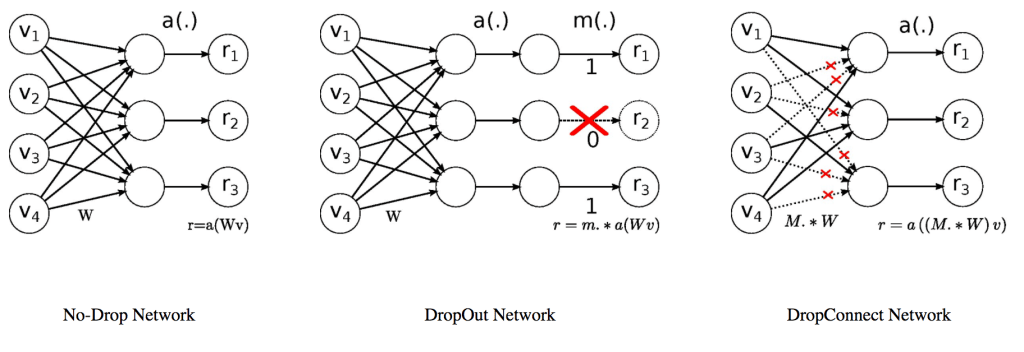
DropConnect Implementation in Python and TensorFlow
I wouldn’t expect DropConnect to appear in TensorFlow, Keras, or Theano since, as far as I know, it’s used pretty rarely and doesn’t seem as well-studied or demonstrably more useful than its cousin, Dropout. However, there don’t seem to be any implementations out there, so I’ll provide a few ways of doing so.
-
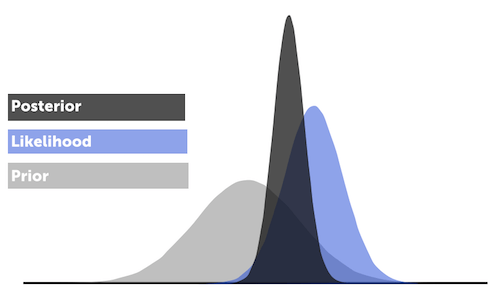
MLE, MAP, and Naive Bayes
Suppose we are given a dataset of outcomes from some distribution parameterized by . How do we estimate ? For example, given a bent coin and a series of heads and tails outcomes from that coin, how can we estimate the probability of the coin landing heads?
-
Shallow Parsing for Entity Recognition with NLTK and Machine Learning
Getting Useful Information Out of Unstructured Text Let’s say that you’re interested in performing a basic analysis of the US M&A market over the last five years. You don’t have access to a database of transactions and don’t have access to tombstones (public advertisements announcing the minimal details of a closed deal, e.g. ABC acquires XYZ for…

-
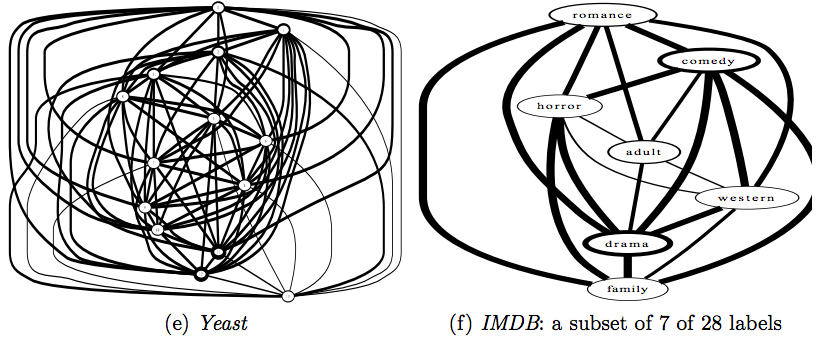
Multi-label Classification: A Guided Tour
Introduction I recently undertook some work that looked at tagging academic papers with one or more labels based on a training set. A preliminary look through the data revealed about 8000 examples, 2750 features, and…650 labels. For clarification, that’s 2750 sparse binary features (keyword indices for the articles), and 650 labels, not classes. Label cardinality…
-
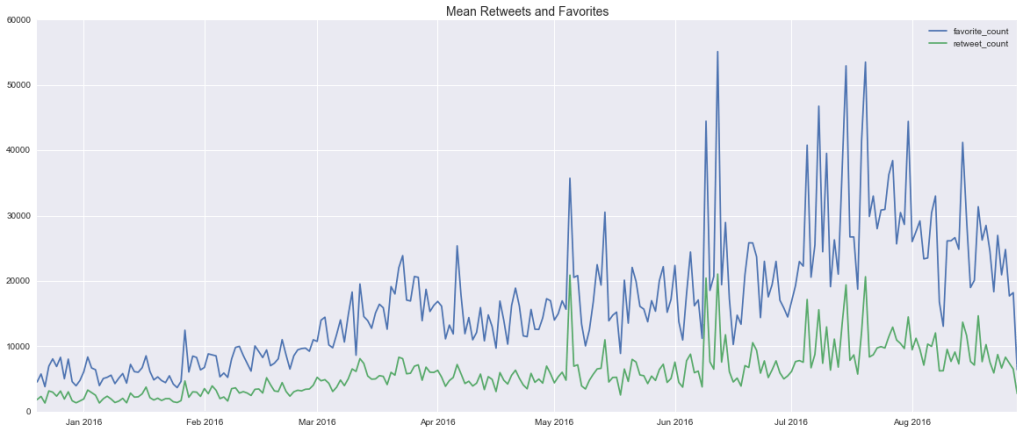
Trump Tweet Analysis
This project stems from two overarching questions: Which emotions do politicians most frequently appeal to? I recently saw a BuzzFeed presentation on, among other things, the virality of BuzzFeed content. A big part of their business relies on understanding what kind of content goes viral and why, so their data science team understandably spends a lot…
-
Article Classification and News Headlines Over Time
How does front page news track a single topic over a period of time? What’s the media’s attention span for a given story? In general, many find it surprising how quickly major media outlets shift their attention from one story to another. This is partly a reflection of our own attention spans and appetites, and…
