I wouldn’t expect DropConnect to appear in TensorFlow, Keras, or Theano since, as far as I know, it’s used pretty rarely and doesn’t seem as well-studied or demonstrably more useful than its cousin, Dropout. However, there don’t seem to be any implementations out there, so I’ll provide a few ways of doing so.

For the briefest of refreshers, DropConnect (Wan et al.) regularizes networks like Dropout. Instead of dropping neurons, DropConnect regularizes by randomly dropping a subset of weights. A binary mask drawn from a Bernoulli distribution is applied to the original weight matrix (we’re just setting some connections to 0 with a certain probability):
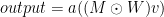
where a is an activation function, v is input matrix, W is weight matrix, 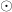
Pure Python:
import operator
import numpy as np
def mask_size_helper(args):
# multiply n dimensions to get array size
return reduce(operator.mul, args)
def create_dropconnect_mask(dc_keep_prob, dimensions):
# get binary mask of size=*dimensions from binomial dist. with dc_keep_prob = prob of drawing a 1
mask_vector = np.random.binomial(1, dc_keep_prob, mask_size_helper(dimensions))
# reshape mask to correct dimensions (we could just broadcast, but that's messy)
mask_array = mask_vector.reshape(dimensions)
return mask_array
def dropconnect(W, dc_keep_prob):
dimensions = W.shape
return W * create_dropconnect_mask(dc_keep_prob, dimensions)
TensorFlow (unnecessarily hard way):
def dropconnect(W, p):
M_vector = tf.multinomial(tf.log([[1-p, p]]), np.prod(W_shape))
M = tf.reshape(M_vector, W_shape)
M = tf.cast(M, tf.float32)
return M * W
TensorFlow (easy way / recommended):
def dropconnect(W, p):
return tf.nn.dropout(W, keep_prob=p) * p
Yes, sadly after a good amount of time spent searching for existing implementations and then creating my own, I took a look at the dropout source code and found that plain old dropout does the job so long as you remember to scale the weight matrix back down by keep_prob. After realizing that a connection weight matrix used for DropConnect is compatible input for the layer of neurons used in dropout, the only actual implementation difference between Dropout and DropConnect on TensorFlow is whether or not the weights in the masked matrix get scaled up (to preserve the expected sum).
I find DropConnect interesting, not so much as a regularization method but for some novel extensions that I’d like to try. I’ve played around with using keep_prob in our new DropConnect function as a trainable variable in the graph so that, if you incorporate keep_prob into the loss function in a way that creates interesting gradients, you can punish your network for the amount of connections it makes between neurons.
More interesting would be to see if we can induce modularity in the network by persisting dropped connections. That is, instead of randomly dropping an entirely new subset of connections at each training example, connections would drop and stay dropped perhaps as a result of the input data class or the connection’s contribution to deeper layers. For another post…
