tutorial
-
XLNet Fine-Tuning Tutorial with PyTorch
Another one! This is nearly the same as the BERT fine-tuning post but uses the updated huggingface library. (There are also a few differences in preprocessing XLNet requires.)
-
BERT Fine-Tuning Tutorial with PyTorch
Here’s another post I co-authored with Chris McCormick on how to quickly and easily create a SOTA text classifier by fine-tuning BERT in PyTorch. This was created when BERT was pretty new and exciting, but the tooling for it was quite bad. Huggingface hosted the model, but documentation was very poor. As a result of…
-
BERT Word Embeddings Tutorial
Check out the post I co-authored with Chris McCormick on BERT Word Embeddings here. We take an in-depth look at the word embeddings produced by BERT, show you how to create your own in a Google Colab notebook, and tips on how to implement and use these embeddings in your production pipeline. This was created…
-
Multi-label Classification: A Guided Tour
Introduction I recently undertook some work that looked at tagging academic papers with one or more labels based on a training set. A preliminary look through the data revealed about 8000 examples, 2750 features, and…650 labels. For clarification, that’s 2750 sparse binary features (keyword indices for the articles), and 650 labels, not classes. Label cardinality…
-
Article Classification and News Headlines Over Time
How does front page news track a single topic over a period of time? What’s the media’s attention span for a given story? In general, many find it surprising how quickly major media outlets shift their attention from one story to another. This is partly a reflection of our own attention spans and appetites, and…
-
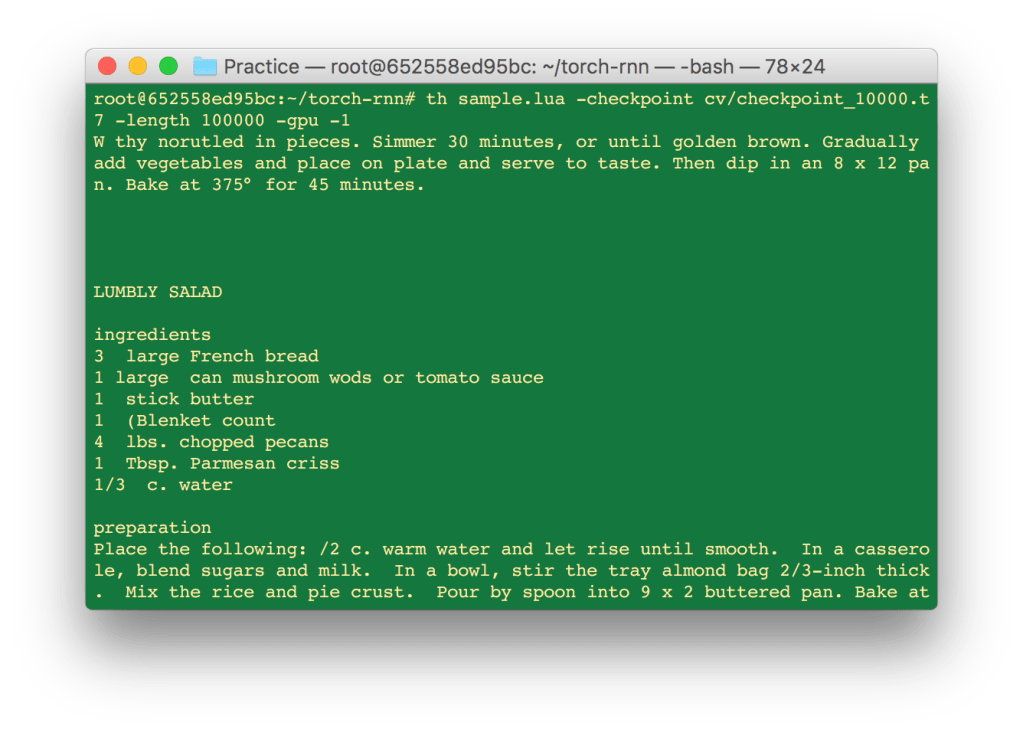
Building a Recurrent Neural Network to Generate Novel Text
Introduction The purpose of this quick tutorial is to get you a very big, very useful neural network up and running in just a few hours. The goal is that anyone with a computer, some free time, and little-to-no knowledge of what neural networks are or how they work can easily begin playing with this…
-
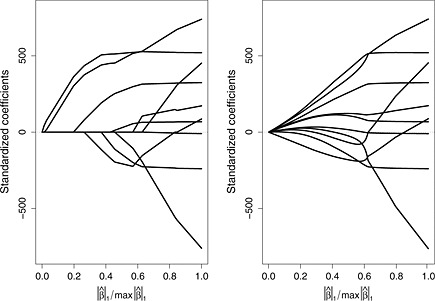
Introduction to Regularization
What is regularization? Regularization, as it is commonly used in machine learning, is an attempt to correct for model overfitting by introducing additional information to the cost function. In this post we will review the logic and implementation of regression and discuss a few of the most widespread forms: ridge, lasso, and elastic net. For simplicity, we’ll…
-
Short Introduction to PCA
In Principal Component Analysis (PCA), we would like to convert our high-dimensional dataset onto a lower-dimensional space while keeping as much information as possible. Typically, this is done to avoid curse of dimensionality effects or for the purposes of data visualization. In broad strokes, PCA reduces the dimensionality of our dataset in a way that…