What is regularization? Regularization, as it is commonly used in machine learning, is an attempt to correct for model overfitting by introducing additional information to the cost function. In this post we will review the logic and implementation of regression and discuss a few of the most widespread forms: ridge, lasso, and elastic net. For simplicity, we’ll discuss regularization within the context of least squares linear regression, and I assume that you have some familiarity with linear regression. Onward!
Regularized regression aims to minimize overfitting by adding a regularization term to our models. This regularization term is added to, in this instance, a standard least squares linear regression cost function 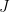
![J(\Theta) = 1/2m [ \sum\limits_{i=1}^{m} (h_\Theta(x^i) - y^i)^2 + \lambda \sum\limits_{j=1}^{n} \Theta^2_j]](https://s0.wp.com/latex.php?latex=J%28%5CTheta%29+%3D+1%2F2m+%5B+%5Csum%5Climits_%7Bi%3D1%7D%5E%7Bm%7D+%28h_%5CTheta%28x%5Ei%29+-+y%5Ei%29%5E2+%2B+%5Clambda+%5Csum%5Climits_%7Bj%3D1%7D%5E%7Bn%7D+%5CTheta%5E2_j%5D&bg=ffffff&fg=000&s=0&c=20201002)
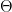







The important thing to notice is the addition of 
When minimizing the cost as a function of our parameter values 


(Note that we ignore the intercept value 
This rearranged formulation gives us the first term 
As if often the case, the best way to get an intution for how this performs on a given dataset is to plug in a couple of values for the regularization parameter 


Thus, adding regularization to our regression estimator can in many instances give us a rough bias/variance dial with which we can address the overfitting of our estimator onto the training set.
Lasso Regression (L1 Regularization) and Ridge Regression (L2 Regularization)
In discussing regularization we employed L2 regularization, also known as Tikhonov regularization and most well known as instantiated in Ridge Regression. This is one particular method of regularization. L1 regularization, most well-known in Lasso regression, is another such strategy for controlling overfitting. The two techniques share the same goal but differ in a few key respects. I find that it’s somewhat easier to explore the specific properties of these different approaches when we put them side by side and can contrast their differences. Since we have covered in broad strokes what regularization is and why we use it, this section will focus on differences between L1 and L2 regularization.
Recall the regularized cost function above:
The regularization term used in the discussion above can now be introduced as, more specifically, the L2 regularization term:
In contrast to the L1 regularization term:
The difference between L1 and L2 is just that L2 uses the sum of the square of the parameters, while L1 is the sum of the absolute value of the parameters. However slight the difference might seem, there are some important consequences that should be considered before deciding which regression strategy to use.

It’s worth mentioning that although L1 and L2 regularization are probably the most discussed and well-known form of regularization, they are not the only forms. In fact, both L1 and L2 fit into the general class of loss function vector norms:

where p=1 for L1 regularization and p=2 for L2 regularization.
What happens to the parameters as regularization changes?
In many cases, L1 regularization will, with a high enough

An explanation comes from examining the shape of the L1 and L2 regularization curves. For L1 regression, the absolute value loss function 


For L2 regression, the absolute value loss function

Recalling gradient descent minimization of the loss function, our parameters are updated according to this loss function. For L1 regularization, the stepwise reduction in
Consider also that our regularized loss function:
![J(\Theta) = 1/2m [ \sum\limits_{i=1}^{m} (h_\Theta(x^i) - y^i)^2 + \lambda \sum\limits_{j=1}^{n} \Theta^p_j]](https://s0.wp.com/latex.php?latex=J%28%5CTheta%29+%3D+1%2F2m+%5B+%5Csum%5Climits_%7Bi%3D1%7D%5E%7Bm%7D+%28h_%5CTheta%28x%5Ei%29+-+y%5Ei%29%5E2+%2B+%5Clambda+%5Csum%5Climits_%7Bj%3D1%7D%5E%7Bn%7D+%5CTheta%5Ep_j%5D&bg=ffffff&fg=000&s=0&c=20201002)
…can be rearranged once more in a manner that simply recastes the function as an unregularized loss function subject to the constraint:

…where 



Here the x- and y-axes represent the case of regularized regression with only two parameters 

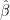
Elastic Net
The Elastic Net penalty is another interesting option for regularization. It combines both the L1 and L2 term in an attempt to combine their strengths:

Specifically, the creators of the Elastic Net wanted to preserve the feature selection property of L1 regression while preserving grouping: if multiple variables are collinear, L1 tends to arbitrarily select one variable from that group while eliminating the others. In addition, L1 can lead to situations in which there is more than one prediction curve that appropriately minimizes the cost function. If L1 arbitrarily chooses one of those two, it is possible that a slight change in the value of one datapoint could cause the regression curve to “jump” to an entirely different curve because the new curve has suddenly had the minized cost fuction tipped in its favor.
Introducing L2 regularization helps to address the problems with L1 while preserving its feature selection property.
___
[Elements of Machine Learning, by HTF, Chapter 3.4 is a great resource](https://www.quora.com/What-is-the-difference-between-L1-and-L2-regularization)
[Andrew Ng’s machine learning lectures on regularization](https://www.coursera.org/learn/machine-learning/home/week/3)
[Presentation by Zou and Hastie, creators of Elastic Net](http://web.stanford.edu/~hastie/TALKS/enet_talk.pdf)
[Insightful discussion and links about L1 vs. L2 here…](http://stats.stackexchange.com/questions/45643/why-l1-norm-for-sparse-models)
[…and here](https://www.quora.com/What-is-the-difference-between-L1-and-L2-regularization)
