In Principal Component Analysis (PCA), we would like to convert our high-dimensional dataset onto a lower-dimensional space while keeping as much information as possible. Typically, this is done to avoid curse of dimensionality effects or for the purposes of data visualization.
In broad strokes, PCA reduces the dimensionality of our dataset in a way that minimizes (certain aspects of) the amount of information we throw away by projecting our 
We take the mean-centered, normalized 


PCA works by first computing the covariance matrix of our features (alternatively, computing the scatter matrix and scaling the eigenvalues later), the covariance matrix somewhat confusingly being denoted with sigma, not to be confused with summation notation:

where 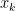


The diagonal values of the covariance matrix 



where
Now we have a set of eigenvectors in our 

What we would like to do is reduce the dimensionality of our dataset while controlling and minimizing the amount of information lost in doing so. The eigenvectors with the lowest eigenvalues generally have the least information about our dataset, so it makes most sense to eliminate these eigenvectors first. The sum of the eigenvalues is the total explained variance, and accordingly the percentage of explained variance associated with each eigenvector/eigenvalue pair is eigenvalue 

We then transform the data by projecting it onto the q-dimensional subspace. Intuitively, we have created a new set of axes and kept the onces which do a good job of capturing the variance in our data. Each eigenvector is centered in our data “cloud,” and we have chosen the axes within that cloud pointing in a 


Note that this process is not the same as feature selection; the orthogonal basis vectors we created do not directly correspond to specific features of the original dataset. Nor should PCA be used as a substitute for feature selection because while it does eliminate the dimensionality of the data, techniques specifically designed for this purpose such as L1 regularization or library instances of feature selection should perform at least as well in doing so, and probably better. PCA is primarily employed to reduce the dimensionality of the data, agnostic of features, and for purposes of visualization.
In practice, singular value decomposition (SVD) also gets us eigenvectors and their corresponding eigenvalues, and is often used for computational precision due to possible rounding errors in the extra step of computing the covariance matrix.
___
[An excellent step-by-step walkthrough in Python by Sebastian Raschka](http://sebastianraschka.com/Articles/2014_pca_step_by_step.html#sections)
[A good set of answers and links for developing PCA “intuition”](http://stats.stackexchange.com/questions/2691/making-sense-of-principal-component-analysis-eigenvectors-eigenvalues/140579#140579)
