“A Neural Algorithm of Artistic Style” is an accessible and intriguing paper about the distinction and separability of image content and image style using convolutional neural networks (CNNs). In this post we’ll explain the paper and then run a few of our own experiments.
To begin, consider van Gogh’s “The Starry Night”:

The content of this picture refers to things like a tree in the foreground, the spired church, the small houses at the foot of the hills, stars, the moon, etc. while the style would refer to, well, van Gogh’s style: dark outlines around objects, almost uniformly thick brushstrokes across the entire image regardless of distance, swirls, the color palette bounded by indigos and blues and soft yellows, etc.
If you’re familiar with CNNs, you’re aware that extracting the content from an image is fairly straightforward because most computer vision applications you’ve worked on are likely concerned with identifying and labeling the content of an image. With a deep CNN we train kernels for low level features like edge detection and high level features like identification of eyes – all content-related features.
We can even take a trained net and examine an individual neuron’s “responsibility” with the network by setting the neighboring layer neuron gradients to 0 and running backpropagation:

(From Justin’s Johnson’s presentation in Stanford CS20: Tensorflow for Deep Learning Research)
Extracting style without content from an image is a less obvious task, and is the main innovation of the paper, which they then put to good use by combining the style from one image with the content of another.

Cool, huh?
Given how well this works to create rich style representations, extrapolation of style from an image is surprisingly simple. Basically, we want to look at correlations between the different filters applied at a given layer. To do this we pass the filter over the image to create the feature maps at our layer, and then we compute the inner product between feature maps of a given layer. The inner product is called the Gram matrix (it’s literally just a matrix dot its transpose), and gives us some intuition about extracting style: if entry 
Here are style reconstructions from “The Starry Night.” a) is the style reconstruction from the lowest layer in our CNN, while each successive style reconstruction combines a higher layer along with all of the previous ones; e) is a combination of the highest CNN layer and all previous ones.

These make sense: in a) we’re seeing the color palette from our 3 channels, and not much else since the lowest CNN filters will be very simple things like edge detection, so their inner product will be a messy and pixelated. As more layers are added and higher-level filters are applied, the style increases in scale and we see more complex “macro-features” of the style that layers deeper in the network will pick up like swirls, wisps, color concentrations (yellow lunar objects) without necessarily seeing any content from the original image.
In order to create hybrid images, the authors devise a novel method of combining style loss and content loss from two images, then perform gradient descent on a white noise image to match the style and content from the respective input images. This is run on a modified version of a pre-trained CNN called VGGNet used for image classification since we need effective pre-trained filters in our network. (VGGNet uses 16 convolutional layers, 5 pooling layers – authors discard fully connected layer and use average pooling instead of max pooling for better results). Our white noise image is fed through the trained CNN and loss is a combination of style and content; each training iteration brings us closer to the style of our style image and the content of our content image.
For a given layer 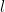

where







Gradient descent will penalize our white noise image for diverging from our content image, and weights will be updated such that our white noise image comes to resemble our content image.
For the style loss in a given layer


where




Finally, to get the total loss objective function we just combine style loss and content loss with weighting parameters:

There are a lot of hyperparameters to tune like which style layers to include, what weights to give to each style layer, noising on the image to be generated, the alpha/beta ratio in the total loss function, not to mention plain old neural net things like learning rate and number of iterations. For this reason (and because it takes 20 minutes per image on my machine), my images won’t look as nice or tuned as those in the paper, but you’ll still get the idea and see how parameter changes affect results. An obvious parameter to change is the alpha/beta ratio to control more vs. less style. Inclusion, exclusion, and weighting of high and low layers for the style loss is another. Another interesting and less obvious parameter has to do with resizing the style image – your hybrid image will contain features at different scales depending on the size of your style image:

If you want to run these yourself the code is available from Chip Huyen’s Tensorflow for Deep Learning course at Stanford, which I highly recommend if you’d like to get good at Tensorflow and see (read: steal) some high quality TF frameworks. It’s an assignment in the class, so it’s worth implementing the mathematical details of the paper yourself, though solutions are included.
There’s another implementation here which I haven’t tried. It’s less involved and uses a VGG implementation that’s much easier to handle, though in either case you will have to download a trained image classification network (.5 GB). On the downside it doesn’t look like it offers logging or examination with tensorboard:

The Stanford code comes with some style images and a content image in case you want to see Deadpool mixed with Picasso:



I wanted to test my intuition on this, so gave the system some tasks I though it would struggle to combine:



As expected, the Beardsley image isn’t well suited to the mathematical definition of style as the Gram matrix. Beardsley’s “Peacock” has lots of isolated pockets with wildly different styles and the granularity of detail (and the uniformity of detail) doesn’t hold across the image. If you asked a human to combine these images, they would probably robe the business people engaged in the rather obscure/invisible tug-of-war with intricately decorated cloaks. In general, you want style images that have stylistic similarities across the image in scale and detail, which is why the style images used in the paper and successful style transfers tend to be impressionist or highly patterned.
I didn’t think it wouldn’t work, but couldn’t resist trying to Simpsonize a family on their couch:


A little cartoony, but also nightmare-fuel. Lots of little blue-haired Homers and one Leela (second on the left).
Let’s try some hyperparameter tuning on the following images to better understand style transfer.
Here’s van Gogh on a small village, with 1st and 299th iteration displayed.




When running these pay attention to the loss functions in tensorboard as they might save you a lot of time. The majority of my images saw no significant qualitative change or change in total loss past the first 100 iterations.

Here’s some hyperparameter tuning so you can get a better idea of what different layers contribute to the hybrid:


5 style layers used [‘conv1_1’, ‘conv2_1’, ‘conv3_1’, ‘conv4_1’, ‘conv5_1’]

2 style layers used [‘conv1_1’, ‘conv2_1’]. Note the smaller, tiled, less macroscopic features, as discussed above with style representations in “The Starry Night.”

1 style layer used [‘conv5_1’]. Here we see lots of more complex style features, in distinction to the image above.

