SUMMARY
Applying a single, linear, learnable weight to the skip (identity) component of residual connections slightly improves training performance. It also reveals interesting training dynamics: during training models will select for strong skip connections in early layers but minimal skip connections in middle and later layers. This can result in learned near-zero skip connections in later layers.
Adding skip connection weights to your model is simple, extremely cheap, and benefits model training.
INTRODUCTION
Residual layer connections are a staple of modern deep learning architectures. According to this design, each layer in a network is the addition of the previous layer’s output plus the output of the current layer’s ouptut given the previous layer’s output. More concisely:

Where 
Here is a representative example of a single layer (block) in a modern transformer language model:

In this project we explore a very simple modification, namely multiplying the skip connection by a single learnable parameter 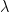

This modification requires extremely minor changes to code (2 lines) and adds only a single parameter per layer of the network….you should try it!

We train a decoder transformer model from scratch on the AllenAI C4 corpus on a single A100. The architecture closely follows best practices in modern LLMs seen here. All code is available here [TODO]. For the following results a model (334M parameters) with the following configuration is used, though the results have been observed on multiple different small (<600M parameter) configurations:
dim=1024
n_layers=16
head_dim=64
hidden_dim=4096
n_heads=16
n_kv_heads=16
norm_eps=1e-5
vocab_size=32000 (mistral 7B tokenizer)
batch_size=16
sequence_length=768
learning_rate=1e-3
adamw_beta=(.9, .95)
weight_decay=.1
MAIN RESULT
By appropriately initializing the skip connections we can achieve a model with faster convergence. The performance benefit is dependent on the skip connection initialization. We have found that initializing the first (few) layers around 1.0 and all subsequent layers to 0.0 is sufficient to obtain faster convergence.
.
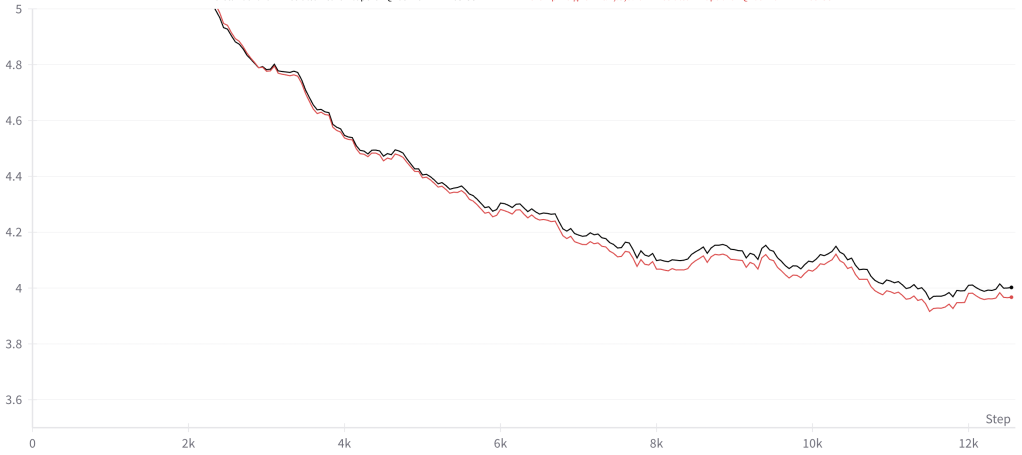

Scale: this approach has only been tested on smaller models (<600M parameters) for limited training runs (<.25B tokens), so experiments at scale still need to be conducted.
Generalization: while this approach hasn’t been extensively tested on other architectures, results have held across a number of transformer decoder architecture configurations. Anecdotally this approach has also worked on a series of experimental architectures based on the transformer decoder architecture suggesting the benefit of skip weights may generalize well (more testing is needed).
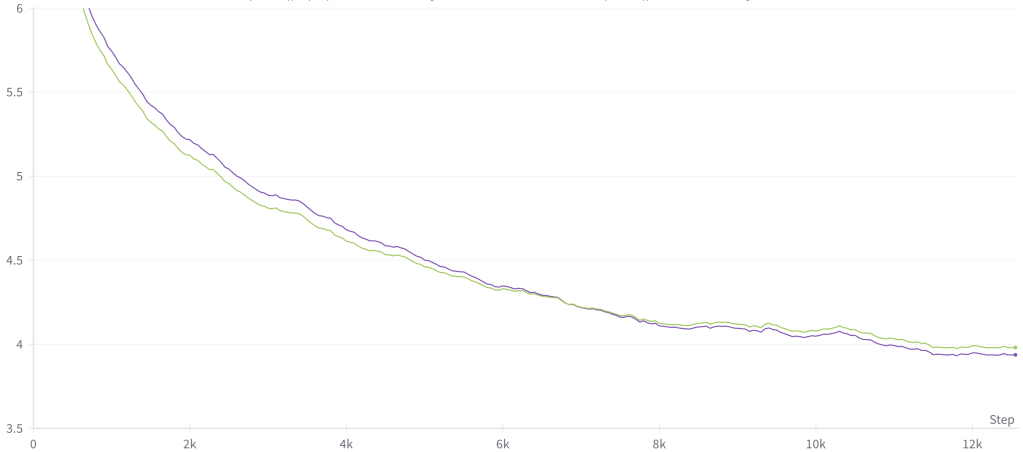
SKIP CONNECTION BEHAVIOR AND INITIALIZATION
If we add learnable skip connection weights initialized at 1.0, we see the following behavior in these weights during the course of training:

In general, the skip connection on the first layer(s) always increases greatly. This is in accordance with the theory that skip connections are especially important in early layers and early training to stabilize the model by passing the identity through to later layers.
The skip weights in the middle and later layers, however, decrease during training. The weights in middle layers converge to zero or negative weights, while those in the last few layers tend to settle somewhere inbetween. (As a followup, it is worth investigating whether high skip weights in the last layers indicates a layer is redundant.)
The working hypothesis is that 1) early layers of the model drastically change the input representation and so benefit from a high identity (skip) signal, 2) the residual component of middle and later layers in the network are very successful at transforming the data into the output representation, so much so that adding identity (skip) signal actually hurts training, therefore the model decreases the skip weights at these layers.
In theory, by providing adaptive skip connections, the model can selectively boost the identity signal where stability is needed and dampen the identity signal where the contribution from the residual component is advantageous. Allowing the model to adjust these single, per-layer scalar parameters is preferable to skip weights fixed at 1.0 (as is current standard practice) where the model must adjust the rest of its millions of parameters in order to boost or dampen the fixed skip signal against competing signals from the skip and residual components.
Simply put, adaptive skip weights are a cheap and efficient mechanism for the model.
Different Initializations of the Skip Weights
The benefit of adaptive skip weights is dependent on their initialization. Above we have seen the behavior of the skip weights at each layer over the course of training when initialized at 1.0
Here we can see what happens if we initialize the skip weights at 0.0:
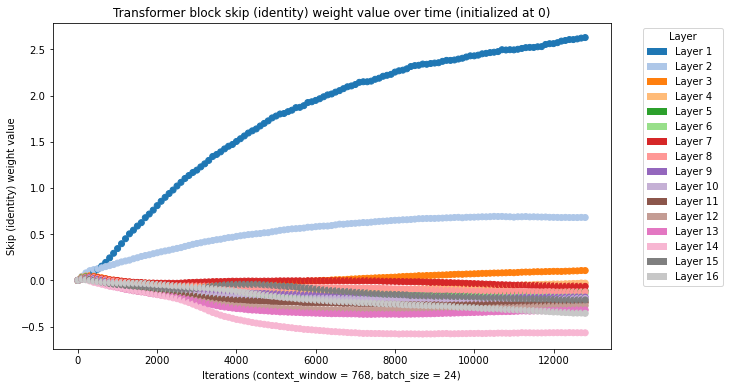
Here with all skip weights initialized at 0.0, but 1.0 at the first layer:
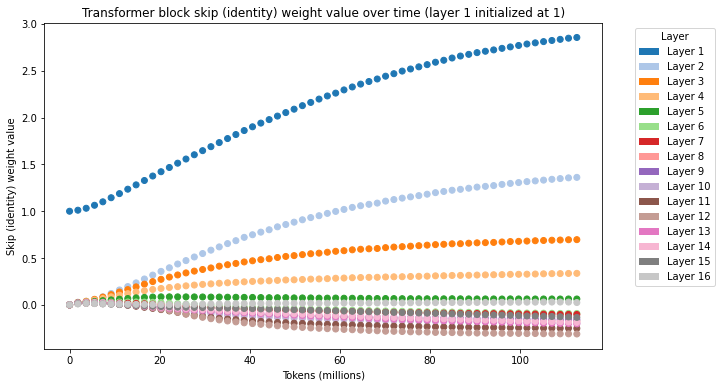
And here with all skip weights initialized at 0.0, but 1.0 at the first layer and 0.5 at the second layer:
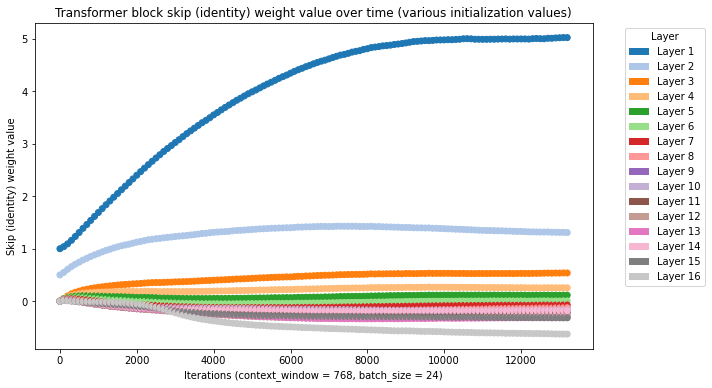
Across all of these initializations a similar pattern emerges (though we have not exhausted the search space of initialization values): a high skip weight for the first few layers and lower skip weights for subsequent layers.
For some initialization configurations, namely all layers initialized at 1.0 or 0.0, the model performs slightly worse or converges to baseline after several thousand iterations.
The general skipweight configuration that results in an improvement is as follows: high (1.0) initialization for the first layer(s) and low (0.0) initialization for the later layers.
In the best performing runs, the weight initialization used is simply: 1.0 for first layer, 0.5 for second layer, 0.0 for all remaining layers (sixteen layer model). It is likely that further exploration in the search space of skip weight initializations can yield better performance, for example weights > 1.0 in early layers or scaled decay of weights for further layers.
Obviously for networks of different depth it is very likely that good initialization looks different.
We did not observe any notable improvement from the following skip weight schemes:
- sigmoid, tanh, or other methods to sharpen/dampen the weight gradient
- weights applied to the residual (this approach is very common in the literature, explored only briefly here)
- weights applied to both the skip and residual
- gating (e.g. sigmoid) weight between the skip and residual, or otherwise data-dependent modifications
- d-dimension vector of weights rather than a single scalar weight
- adding a small amount of Gaussian noise to the initializations didn’t affect the behavior of the weights
RELATED WORKS / LORE
Deep Residual Learning for Image Recognition (ResNet) and Highway Networks were the first to popularize residual connections for deep learning. Highway Network authors use a sigmoid gating function (with d-dimensional weight and bias vectors) to balance the residual and skip (called “transform” and “carry” respectively, borrowing from LSTM literature). They find success in initializing the bias vectors very negative, which results in the network heavily weighting the skip connections and minimizing the residual at the start of training.
In a follow-up to the ResNet paper, Identity Mappings in Deep Residual Networks, the authors explore different initializations and weighting schemes to balance the skip and residual connections, including gating, convolutions, constant scaling, and dropout.
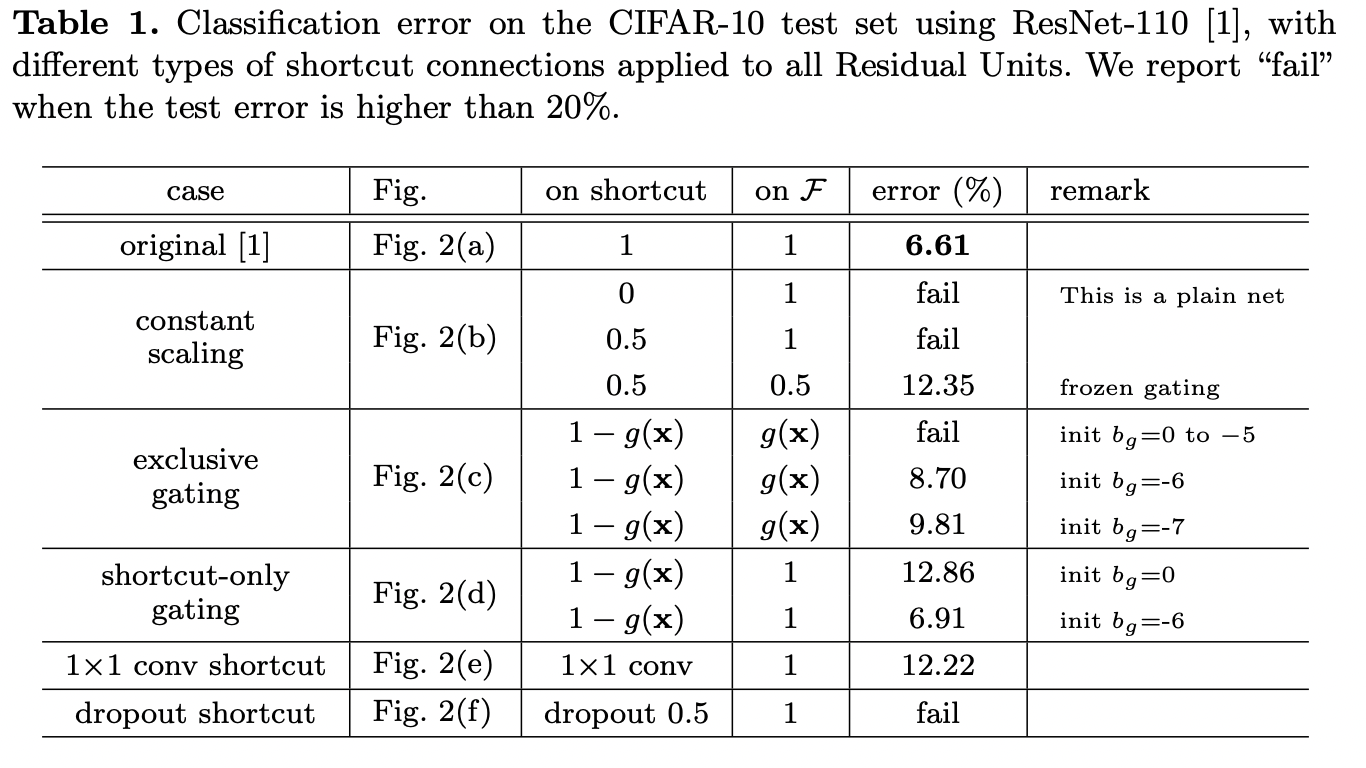
Ultimately he authors found that a fixed value of 1.0 * residual and 1.0 * skip connection were best. The authors didn’t test parameterized weights, only fixed weights.
An important thing to note is that bad initializations and bad schemes are “bad” in many cases because these networks failed to converge. Therefore we can revisit – under more modern, stable architectures and optimization paradigms – these initialization schemes to determine whether they failed because they are actually worse, or because the architectures and optimization were too unstable to allow them to offer any benefit.
The authors specifically discuss the introduction of a multiplicative skip weight, pointing out that the weight value (if greater or less than 1.0) will become exponentially large or small, meaning the gradient on the skip connections will dominate or vanish:
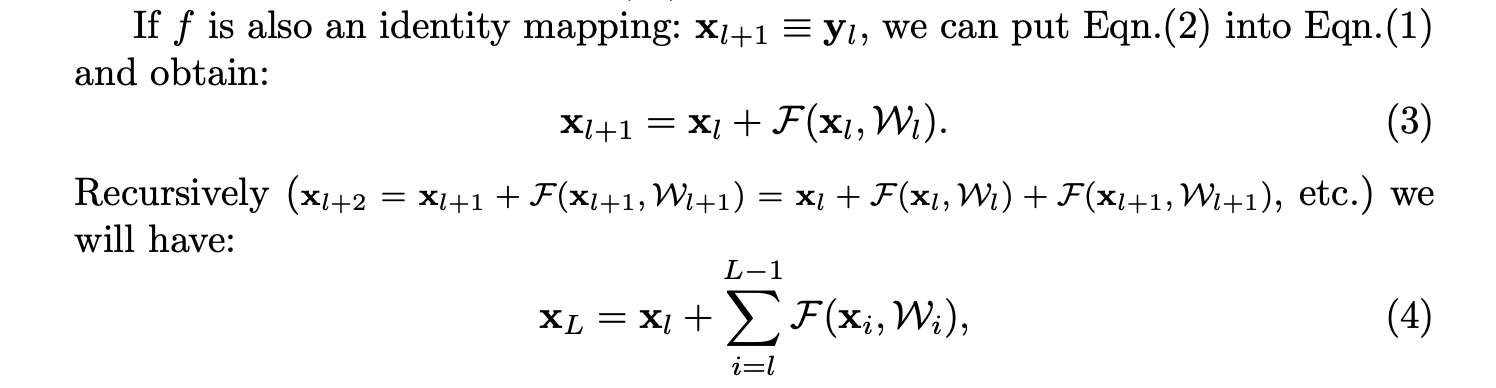

Both ReZero and Weighted Residuals for Very Deep Networks propose an adaptive weight on the residual component at each layer initialized at 0, though for different reasons. The former takes off from the theory of dynamical isometry (basically, for good trainability, the singular values of the Jacobian should be close to 1), and the latter wants better performance and to address non-negative nonlinear functions in relation to additive residual connections.
This last point is worth noting: many nonlinear activation functions only output positive values, so if skip connections are just positive additions and the residual is always non-negative, the skip/residual signal gets continually boosted when it should be taking on negative values. However in most modern cases, this is resolved by the placement of the residual connection, which doesn’t follow the non-linearity directly, but rather follows something like convolution(nonlinearity(x)) or MLP(nonlinearity(x)).
Rethinking Skip Connection with Layer Normalization takes a closer look at skip connection weights, but is primarily interested in their position within the network. Skip weight connections are fixed greater than or equal to 1. The authors briefly discuss parameterized/adaptive skip weights, but then state “the findings are not in favor of this approach over the fixed scalar version.”
Further use and discussion of weighted skip connections is somewhat few and far between. This paper includes some discussion of weighted skip connections, but the weights are bounded [0,1], and there’s little analysis of these weights. This paper uses a somewhat involved gating function on the skip connections for retinal vessel segmentation.
There is some resemblance between skip connections in transformer models and gating mechanisms in recurrence models: early research on the residual and skip connection often even borrows the terminology of LSTMs and tries the gating mechanisms successful in that domain. Further research can look further into this loose connection, possibly examining the newest generation of recurrence and state space models for inspiration.
Not strictly related to adaptive skip weights but nevertheless useful for thinking about the role of skip weights, this paper interprets residual networks as ensembles composed of the 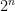
Interestingly, deleting or shuffling one or multiple paths doesn’t explode the loss, but gradually degrades it in proportion to the number of corrupted paths. Furthermore, when looking at all
There’s more interesting work that examines to whether deep models are a hierarchical computation of increasingly abstract representations at each layer, or more like iterative refinement of data.
DISCUSSION
Revisiting old ideas under new architectures
As mentioned above, it is possible that while residual connections were added to stabilize earlier, more unruly networks, today we are at a point where networks are far more stable on their own (with optimizers, schedules, norms, etc.) and the fixed 1.0 weight on skip and residual connections now slightly inhibits training and can be relaxed.
Most weighting schemes in recent literature focus on boosting in a fixed manner, rather than minimizing or adaptively modifying, the skip connection. Otherwise these schemes are interested in minimizing the residual, for example initializing learnable residual weights at 0. It is somewhat surprising to me, and I would imagine surprising to others, that a network with skip connections would even converge, let alone improve upon a model with fixed skip connections given the record of such approaches in previous literature causing a failure to converge, as was first shown in Identity Mappings in Deep Residual Networks. Multiple works repeat the finding that skip connections, and in particular initializing a network as or near the identity, greatly improves learning. Indeed, minimizing or initializing skip connections to 0 seems like discarding the very innovation of residual connections that has led to so much success.
If nothing else, we should ask the following questions: why does a model with skip connections weighted lower than one still successfully train? (Of course, this approach still needs to be tested at scale, particularly with much deeper networks.)
Interpretation of weight dynamics over training
It’s difficult to exactly interpret the purpose or effect of the skip weight dynamics over training, especially given the difficulty in preciesly interpreting the dynamics of fixed residual connections.
The working hypothesis of adaptive skip weights is something like this: residual connections add stability, and adding learnable parameters allows the model to adjust and in some cases remove the elements of stability that are preventing it from making full use of its residual computation.
Specifically, for early layers of the model this skip weight helps boost the initial representation for later layers to access; all layers benefit from strong access to the initial representation of data in the early layers. Alternatively, the early residuals are less useful to the model, so the skip weights effectively minimize these residuals.
Later layers have valuable residuals, which may be be unnecessarily weakened by a strong skip connection, therefore the skip weights at these layers decrease towards zero.
An unnecessary modification?
In theory the model should have no trouble adapting the residual components around a fixed weight skip connection. Adding a single scalar weight on the skip connection does not change the capacity or functionality of these models at all.
There is some intuition at play, however, that if the model benefits from minimizing the skip connection at layer l, it can accommodate this change by scaling up the signal of the residual component comprised of millions of parameters, balanced against gradient clipping, normalizations, nonlinearities, etc. But an effective alternative is to simply parameterize the skip connection with a single value.
Finally, to come full circle with a quote from the original ResNet paper, “…Although both forms should be able to asymptotically approximate the desired functions (as hypothesized), the ease of learning might be different.”
